
Automatically Caption Your Videos with Whisper and ffmpeg
· 5 min readBig video handlers like YouTube and even Slack use AI to automatically caption videos that you upload. This is a great win for accessibility, and the AI is extremely accurate. It sometimes stumbles on uncommon words and bad audio signals, but these can be easily fixed by a human. I think most would agree that the benefit and cost savings of generating 95% accurate captions greatly outweighs the cost of having none at all!
So at work we were talking about how we could build this feature ourselves using open source tools. I came up with this suggestion that uses OpenAI’s Whisper and the venerable ffmpeg.
There are two steps to this (1) generate captions from the video as an SRT file, and (2) bundle the captions with the video.
Whisper in my experience is incredibly good at audio transcription. And it can directly transcribe mp4 files to SRT format. You don’t have to extract the audio from the video or anything like that. Once you have an SRT file, ffmpeg can easily bundle an mp4 and SRT file. I’ve tried this on some personal videos, and the results have been near perfect.
Installation
Here is my project directory on GitHub. The README includes installation instructions, reproduced here.
https://github.com/whusterj/whisper-transcribe
The only two hard dependencies are the ffmpeg system package and the openai-whisper Python package.
This installation has been tested with Python 3.10.12 on Ubuntu 20.02. It should work on other Platforms as well, and OpenAI says Whisper should work with all Python versions 3.9 to 3.11.
First, you will need ffmpeg on your system, if you don’t have it already:
# on Ubuntu or Debian
sudo apt update && sudo apt install ffmpeg
# on MacOS using Homebrew (https://brew.sh/)
brew install ffmpeg
For other platforms, see the [Whisper GitHub repo][1].
Now you can install the python requirements. Create a virtual environment, activate it, and pip install from requirements.txt:
python -m venv .venv/
source .venv/bin/activate
pip install -r requirements.txt
If you encounter errors during installation, you may need to install rust on your platform as well. If my requirements.txt fails to install for some reason, try just installing the openai-whisper package - this should install its Python sub-dependencies:
pip install openai-whisper
How to Do It
Step 1: Use whisper to generate an SRT transcription of the video:
whisper infile.mp4 \
--model small.en \
--language English \
-f 'srt'
I tested this on a two minute video and it took less than 30 seconds to produce a complete transcription. This output is a subtitle file for your video - an SRT file. SRT is a plaintext file format, so you can edit it with your word processor of choice. Open the SRT, and you will see that each line of the file contains start and end timecodes and the caption text. This can be interpreted by video players to display the caption at the right time in sync with the video.
I used the small.en language model, which is about 400MB to download. It may be less accurate than the larger models, but in my experience it does a really good job. The option -f 'srt' specifies that you want an SRT file, but you have your choice of text output format.
You may want to quickly review the SRT file for any misinterpreted words or names
Step 2: Use ffmpeg to add the SRT as a subtitle track:
ffmpeg -i infile.mp4 \
-i infile.srt \
-c copy -c:s mov_text \
outfile.mp4
This took less than 2 seconds to run. It doesn’t have to re-render the video, it just bundles the SRT alongside the video track inside of the mp4 container.
You will need a player like VLC that can show you the subtitle tracks. It is also possible to use ffmpeg to “burn in” the subtitles from your SRT file, but this requires re-rendering the whole video.
Automate It All!
The above would be the “by hand” procedure, but perhaps you can see how easily this process might be automated in bulk.
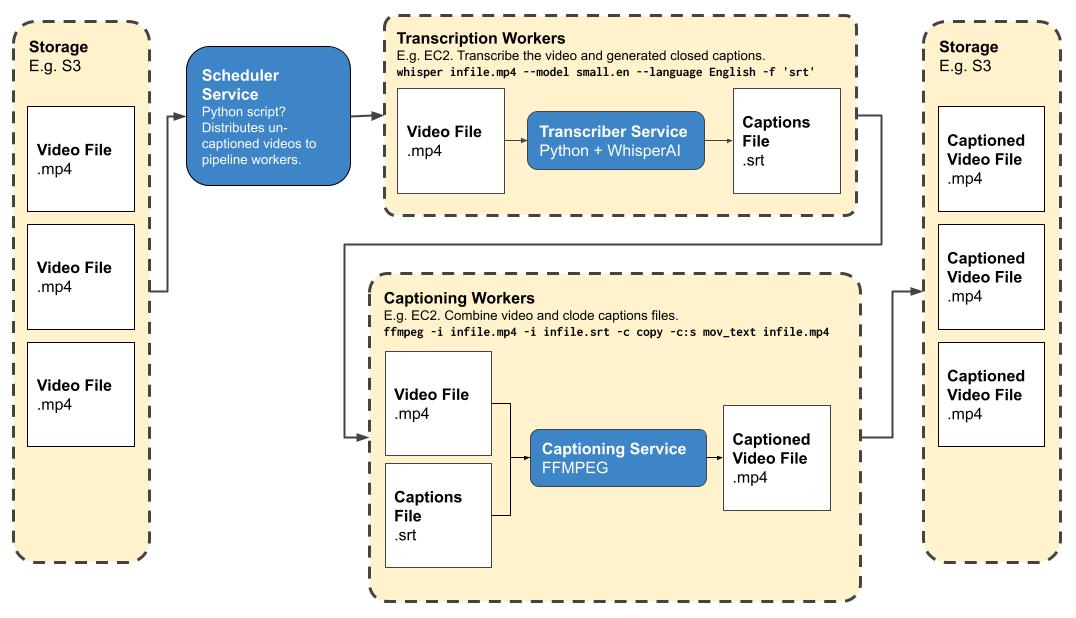 The idea would be that you can drop the mp4 files you want subtitled into an S3 bucket. Then you’d have a scheduler script detect them and queue up jobs for one or more workers. This isn’t strictly necessary, but would allow you to fan out the process to as many workers as you like to process more videos faster. The jobs would run the above commands and produce captioned video files automatically, which are then saved back to S3 somewhere.
The idea would be that you can drop the mp4 files you want subtitled into an S3 bucket. Then you’d have a scheduler script detect them and queue up jobs for one or more workers. This isn’t strictly necessary, but would allow you to fan out the process to as many workers as you like to process more videos faster. The jobs would run the above commands and produce captioned video files automatically, which are then saved back to S3 somewhere.
Show Captions in HTML without Embedding
If you’re captioning videos for viewing in web browsers, there’s an even easier way.
After my initial write-up, I learned that it’s also possible to attach the track to the video using HTML5’s built-in <video> and <track> tags. This cuts out step two above, meaning you won’t have to use ffmpeg to embed the track in the video file.
In this case, you’ll want to generate a .vtt file instead of the .srt above. Fortunately, Whisper supports this format, too!
whisper infile.mp4 \
--model small.en \
--language English \
-f 'vtt'
Once you’ve generated your captions, you can use them with the HTML5 video player like this:
<video src="myvideo.mp4">
<source src="myvideo.mp4" type="video/mp4" />
<track
label="English"
kind="captions"
srclang="en"
src="/path/to/captions.vtt"
default
/>
</video>